Scapeler gebruikt multivariate data analyse tools om de complexiteit van data te onderzoeken. Op basis van multivariate data analyses zijn bijvoorbeeld instelparameters van een productieproces te relateren aan kwaliteitskenmerken van tussenproducten of eindproducten. Ook maken deze analyses het mogelijk om combinaties van instelparameters te detecteren waarbij een proces instabiel wordt of om een meetprocedure te kalibreren. Bij Scapeler gebruiken we het softwarepakket ‘The Unscrambler X’ van CAMO Software (tegenwoordig Aspentech USA).
Heel veel data
Luchtkwaliteit sensoren produceren heel veel data en over een langere periode kan de complexiteit van de data al snel te ingewikkeld worden om dit met simpele statistische technieken te onderzoeken. Een sensorkit stuurt 20 seconden gemiddelde data uit voor vele variabelen zoals de concentratie voor verschillende deeltjes diameters, de massaconcentratie fijnstof voor verschillende deeltjes diameters, de temperatuur, de luchtvochtigheid, de luchtdruk en vaak ook de temperatuur buiten de sensorkit. De hoeveelheid data voor één uur meten komt dan al snel uit op vele duizenden datapunten. Om de grote hoeveelheid aan data te reduceren, kun je gebruik maken van het middelen van de datapunten naar bijvoorbeeld een uurgemiddelde. Je kan je voorstellen, dat het onderzoeken van meerdere dagen of zelfs meerdere weken of maanden een enorme klus zal zijn. Grote databases kunnen wel 100.000 tot miljoenen datapunten bevatten, waarbij meerdere variabelen zijn opgenomen (multivariaat karakter). Vaak bevat een grote database zowel numerieke variabelen (getallen) en tekst variabelen (soort, maand, seizoen). Tevens kan er data van externe bronnen toegevoegd worden aan de database zoals data van de CAMS satelliet, KNMI, RIVM, DCMR en GGD. Om een dergelijk grote database te onderzoeken zijn er krachtige multivariate data analyse technieken beschikbaar.
Data analyse technieken nader bekeken
De meest gebruikte multivariate data analysetechnieken bij Scapeler zijn:
- Beschrijvende statistiek
- PCA : Principale Component Analyse
- MLR : Multivariate Lineaire Regressie
- PLS : Partial Least Squares
Het gaat in deze blog te ver om bovenstaande technieken in detail uit te leggen. Een introductie is te bekijken op Youtube.
Voorbeeld PCA analyse
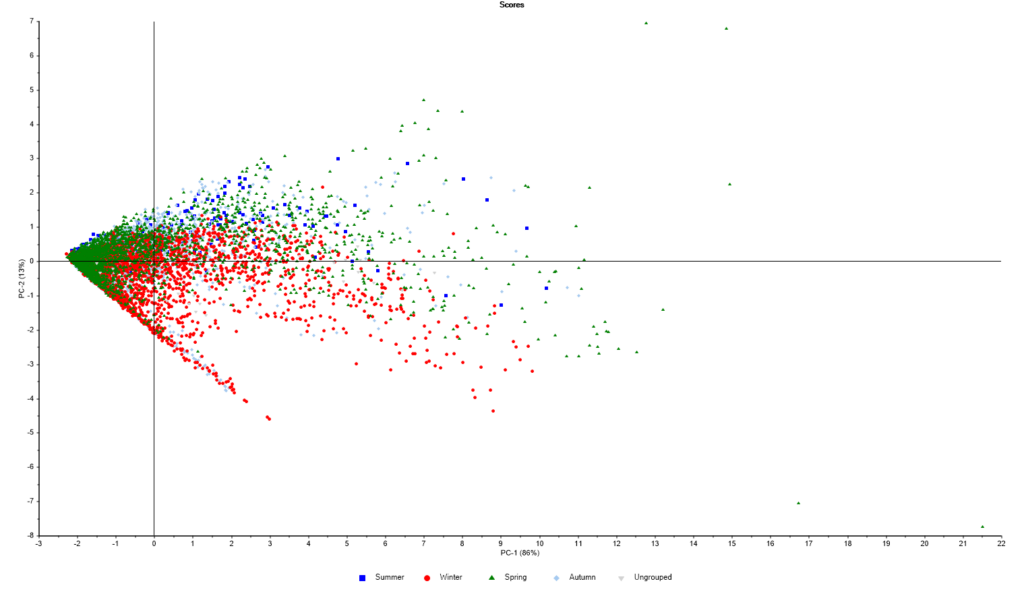
Een voorbeeld van een PCA is in onderstaande figuur weergegeven. Een PCA wordt toegepast om de complexiteit in een database te vereenvoudigen. Hierbij worden de varianties in de variabelen proportioneel verklaard met behulp van zogenaamde Principale Componenten (PC). De eerste PC verklaard de meeste variantie, de tweede PC de één na minste variantie en dat gaat zo door, totdat alle varianties zijn verklaard. Als voorbeeld is een PCA toegepast op de deeltjes data van een Plantower PMSA003 fijnstofsensor. De database bevat 6984 meeturen en 6 variabelen die de deeltjesgrootte beschrijven. In totaal zijn er dus 42.000 datapunten, waarbij het seizoen als tekst variabele is meegenomen. In de figuur zijn de zogenaamde “scores” geprojecteerd op de principale componenten. Elke stipje in de figuur stelt een uur voor met de bijbehorende deeltjes data. De eerste en tweede PC verklaren totaal 99% (86% op PC1 + 13% op PC2) in de variantie van de data. De seizoenen zijn gemarkeerd met een kleur. Er is onderscheid te zien tussen de seizoenen en enkele flinke uitschieters in de lente periode. De meeste meeturen in de winter zijn te zien aan de onderkant van de wolk, voor de meeturen in de zomer juist aan de bovenkant van de wolk. Deze informatie kan worden gebruikt om de complexiteit van de totale database nader te onderzoeken. Het is dan zaak om andere variabelen te betrekken in de analyse, zodat er patronen kunnen worden herkend.
Regressie, kalibratie en modellen
Als de complexiteit van de data is onderzocht, is het mogelijk de structuur te vereenvoudigen en te rangschikken met als resultaat een beter inzicht van de complexiteit. Het kan dan zelfs mogelijk zijn om verschillende variabelen te combineren om hiermee een andere variabele te voorspellen. Deze techniek heet regressie of kalibratie en het resultaat is een (multivariaat) model. Scapeler gebruikt modellen om de nauwkeurigheid en betrouwbaarheid van fijnstof sensoren te vergroten. Een resultaat van het Visibilis project was onder andere een model voor de Plantower fijnstofsensor, waarmee de invloed van temperatuur en luchtvochtigheid wordt gecorrigeerd en de uitkomst is gekalibreerd tegen een referentie fijnstof analyzer.
De XY-relatie plot
De ontwikkeling van dit model kan in een aantal stappen worden uitgelegd. Laten we eerst de relatie bekijken tussen de PM2.5 data van de sensor (X-as) en de PM2.5 data van de referentiemonitor BAM1020 (Y-as). Dat is mogelijk, als de fijnstofsensor en de referentiemonitor dicht bij elkaar zijn geïnstalleerd gedurende een lange periode. De relatie kan gevisualiseerd worden met een XY-scatterplot en is hieronder weergegeven.
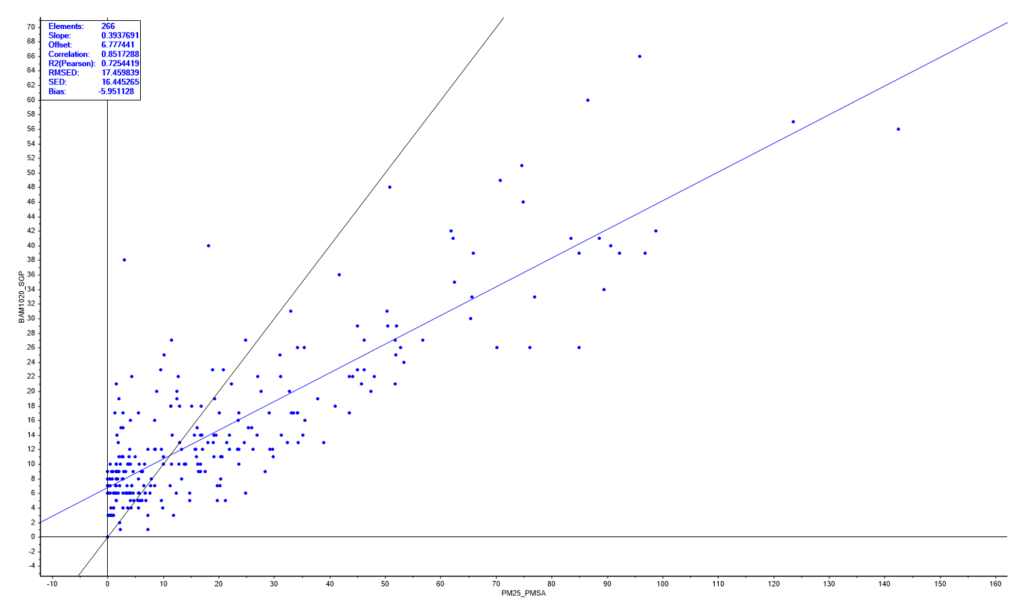
Er zijn 266 meetpunten meegenomen in de relatie. De zwarte lijn is een weergave van een perfecte relatie. De zwarte lijn gaat door de oorsprong (X,Y =0,0) en er geldt de volgende functie: Y=X. De blauwe lijn is de lineaire regressielijn tussen de sensor en de BAM1020 en er geldt de functie: Y=a*X + b. In deze functie staat a voor de richtingscoëfficiënt (in het Engels “slope”) en b voor de afsnede op de Y-as (in het Engels “offset”). De functie van de blauwe lijn wordt dan als volgt: Y = 0.393*X + 6.78 oftewel PM2.5_BAM1020 = 0.393*PM2.5_PMSA + 6.78. Linksboven in de grafiek is een samenvatting van de statistische prestatiekenmerken van de lineaire regressielijn. De fout in de relatie is 17.5 µg/m3.
MLR modellen
Met behulp van een MLR model kan de relatie verbeterd worden met als doel een betere regressielijn met een kleinere fout. In eerste instantie is het model gemaakt waarbij de PM2.5 data van de sensor, de temperatuur en de luchtvochtigheid zijn gekalibreerd tegen de referentiemonitor. De temperatuur en luchtvochtigheid hebben impact op de deeltjesgrootte en dus op de toegekende massa. De meteo is gemeten met een aparte sensor. Het resultaat van de MLR is hieronder weergegeven.
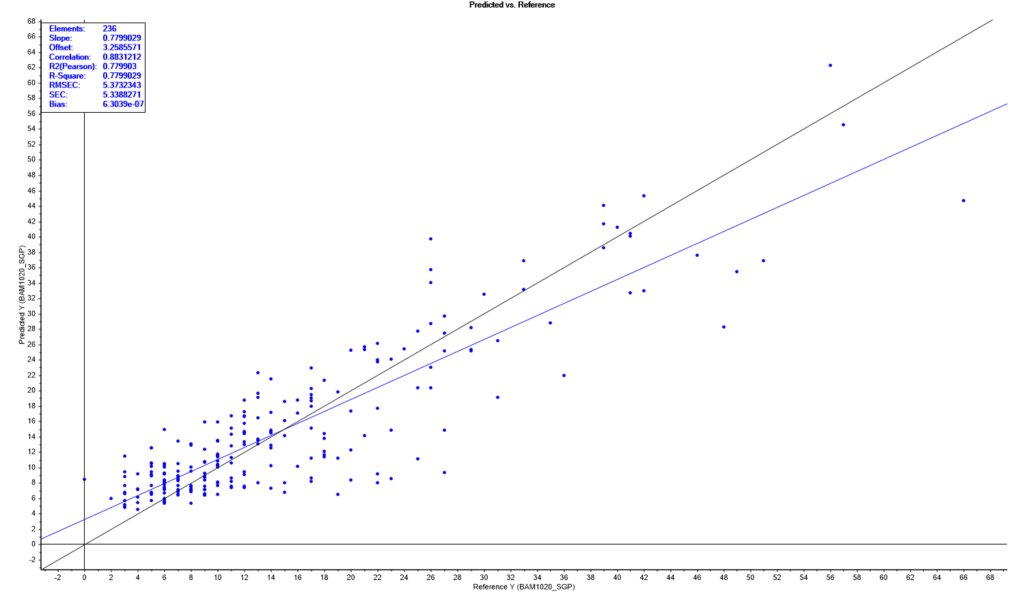
De MLR modelprestaties zijn een stuk beter geworden als we deze vergelijken met de regressielijn uit de XY-scatterplot. We zien, dat de punten meer rondom de zwarte lijn komen te liggen. De slope is met 0.78 bijna een factor twee beter geworden. De offset is met 3.26 meer dan gehalveerd en de fout is met 5.4 µg/m3 een factor drie beter geworden. Het model voorspeld een waarde voor de BAM1020 (“Predicted Y” op de Y-as) en deze wordt vergeleken met de referentiewaarde (“Reference Y” op de X-as). Het model bevat 236 meetpunten.
Kunnen de prestaties van het model nog verder verbeterd worden? Deze vraag kan soms een ware uitdaging zijn. Een fijnstofsensor is in principe een deeltjesteller. Een intern algoritme in de chip van de sensor zet de deeltjesinformatie om in een massaconcentratie. We kunnen dit algoritme omzeilen door gebruik te maken van de ruwe data van de deeltjestelling. Het MLR model is nu gekalibreerd tegen de referentiemonitor waarbij de deeltjesinformatie van de fijnstofsensor, de temperatuur en de luchtvochtigheid als input variabelen zijn gebruikt. Het resultaat van dit MLR model is hieronder weergegeven.
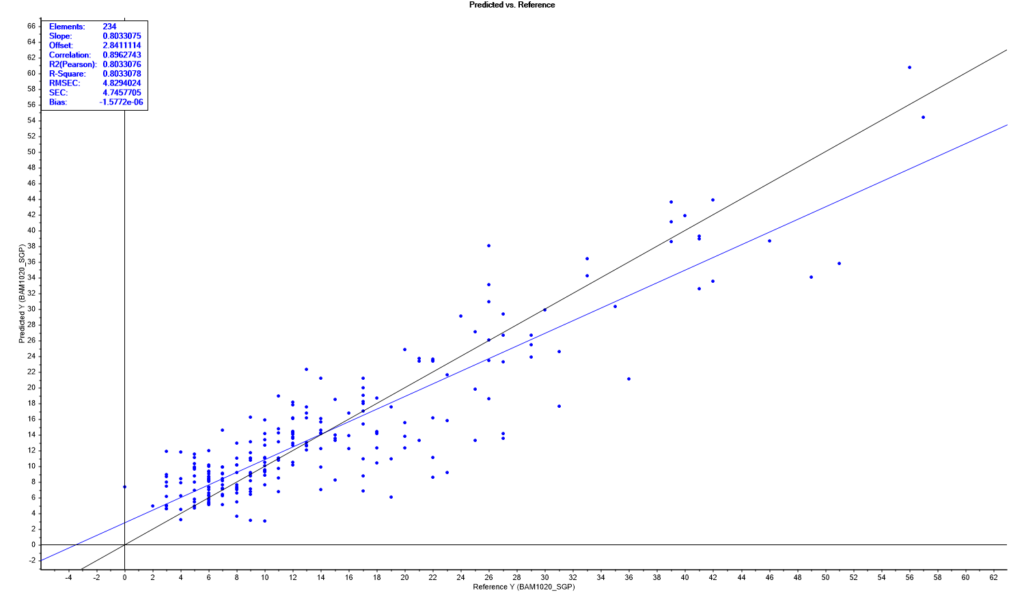
De MLR modelprestaties zijn iets beter geworden als we deze vergelijken met het vorige MLR model. We zien, dat de punten nog iets beter rondom de zwarte lijn komen te liggen. De slope is met 0.80 iets beter geworden. De offset is met 2.84 nog iets lager geworden en de fout is met 4.8 µg/m3 ook verbeterd. Het model bevat 234 meetpunten.
MLR actief op de Aprisensor
Dit model kan actief gemaakt worden binnen de Aprisensor besturingssoftware van de sensor. De sensor fungeert dan als het ware als een BAM1020 referentiemonitor, omdat het model een voorspelling maakt voor de referentiewaarde. Het model kan blijvend gevalideerd worden tegen een referentiestation van RIVM of DCMR. Als het model teveel gaat afwijken, kan het model uitgebreid worden met nieuwe datapunten. Op deze wijze zal het model steeds robuuster en nauwkeuriger worden.

")
